Getting started with our Text Gen Solution
The OctoAI Text Gen Solution offers market-leading price and performance for a growing list open source LLMs including Llama3 and Mistral (see Supported models section below). We offer a WebUI playground, API endpoints, and Python/TypeScript SDK solution for interacting with these models. All of our endpoints are callable via chat completions format currently popular in the industry (see API documentation).
In the coming months, we will launch additional features including efficient fine-tuning, longer-context models, JSON mode support, and other features.
If you have an LLM use case that our existing endpoints do not support, contact us. We offer low-latency and throughput-optimized solutions for all Llama 3 and Mistral checkpoints.
Self-Service Models
We are always expanding our offering of models and other features. Presently, OctoAI supports the following models & checkpoints for self-service models:
Meta-Llama-3.1 Meta’s latest LLM family. Llama-3.1 offers improved understanding and instruction following as compared to Llama-3.0, expands context length, supports 8 languages (English, French, German, Hindi, Italian, Portuguese, Spanish, and Thai), and includes support for function calling. Model is offered in 8B-, 70B-, and 405B-parameter variants. The 405B variant is the most powerful open source model yet released.
Mistral-7b-Instruct-v0.3: Updated by Mistral AI in May 2024, Mistral-7B-Instruct-v0.3 is an instruction-tuned model that achieves high-quality performance at a very low parameter count.Compared to the previous version, this model expands the vocabulary to 32,768, adds support for the v3 Tokenizer, and enabled function calling. Read more. This model is available for commercial use. We offer a single endpoint here: the 7B parameter model, which supports up to 32,768 tokens.
Mistral-8x7b-Instruct: Mistral AI’s December 2023 release, Mistral-8x7b-Instruct, is a “mixture of experts” model utilizing conditional computing for efficient token generation, reducing computational demands while improving response quality (GPT-4 is widely believed to be an MoE model). Mistral-8x7b-Instruct brings these efficiencies to the open-source LLM realm, and it is licensed for commercial use. It supports up to 32,768 tokens. Read more.
Nous-Hermes-2-Mixtral-8x7b-DPO The flagship Nous Research model trained over the Mixtral 8x7B MoE LLM. The model was trained on over 1,000,000 entries of data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks. It supports up to 32,768 tokens.
Mixtral-8x22B-Instruct The instruction fine-tuned version of Mixtral-8x22B represents the latest and largest mixture of experts Large Language Model (LLM) from Mistral AI. Read More. This model employs a mixture of 8 experts within a 22-billion-parameter model, with experts selected dynamically during inference. This architecture enables large models to operate quickly and cost-effectively at inference time. Fluent in five languages, the model excels in mathematics and coding, natively supports function calling. It supports up to 65,536 tokens.
WizardLM2-8x22B A fine tune of Mixtral-8x22b published by Microsoft, competitive with closed source models on a variety of benchmarks. Microsoft specifically trained this model to support complex instruction following, and it has gained a folloiwng with the open source community and OctoAI customers. As with Mixtral-Instruct, this supports up to 65,536 tokens. Read more.
Meta-Llama-3-Instruct Released by Meta in April 2024, the Meta Llama 3 family of large language models (LLMs) uses a optimized decoder-only transformer architecture and is available for commercial use. Llama 3 enhanced Llama 2 with a 128K token tokenizer for improved performance, and grouped query attention for increased inference efficiency. Read more. Llama 3 is trained on a 15 trillion-token dataset, with 5% comprising high-quality multilingual data from over 30 languages. The Llama 3 instruction tuned models are optimized for dialogue use cases. OctoAI offers Llama 3 Instruct model in 8- and 70-billion parameter sizes. It supports up to 8,192 tokens.
Llama Guard 2 An 8B parameter Llama 3-based LLM content moderation model released by Meta, which can classify text as safe or unsafe according to an editable set of policies. As an 8B parameter model, it is optimized for latency and can be used to moderate other LLM interactions in real time. Read more. Note: This model requires a specific prompt template to be applied, and is not compatible with the ChatCompletion API.
GTE Large An embeddings model released by Alibaba DAMO Academy. Trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. Consistently ranked highly on Huggingface’s MTEB leaderboard. In combination with a vector database, this embeddings model is especially useful for powering semantic search and Retrieval Augmented Generation (RAG) applications. Read more.
For pricing of all of these endpoints, please refer to our pricing page.
Web UI playground
You can start familiarizing yourself with our Text Gen features using the web UI, but note that we have even more features available via the API.
First, click on the top navigation bar and click Text Tools. Here you will see the different model families that we offer for self-service users:
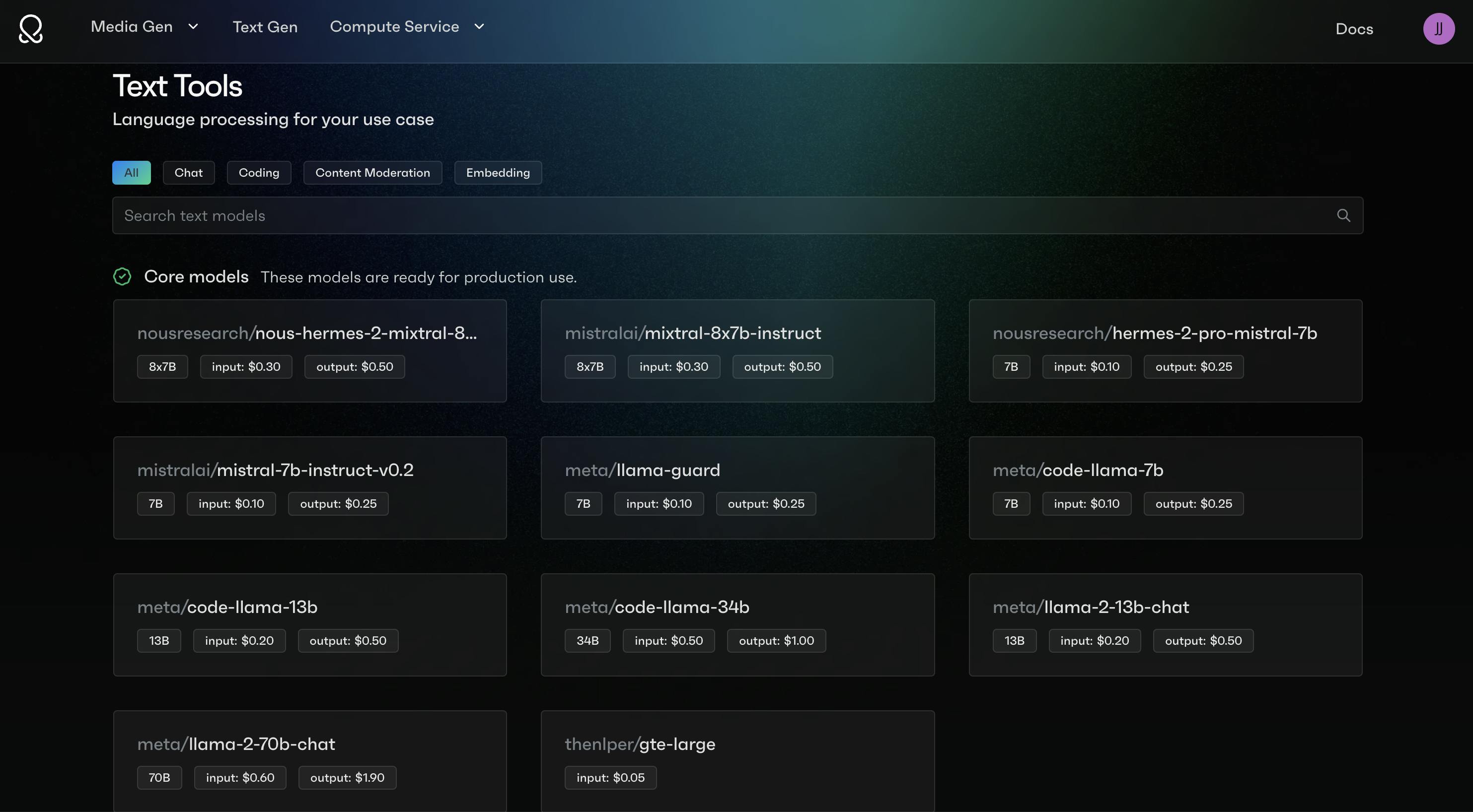
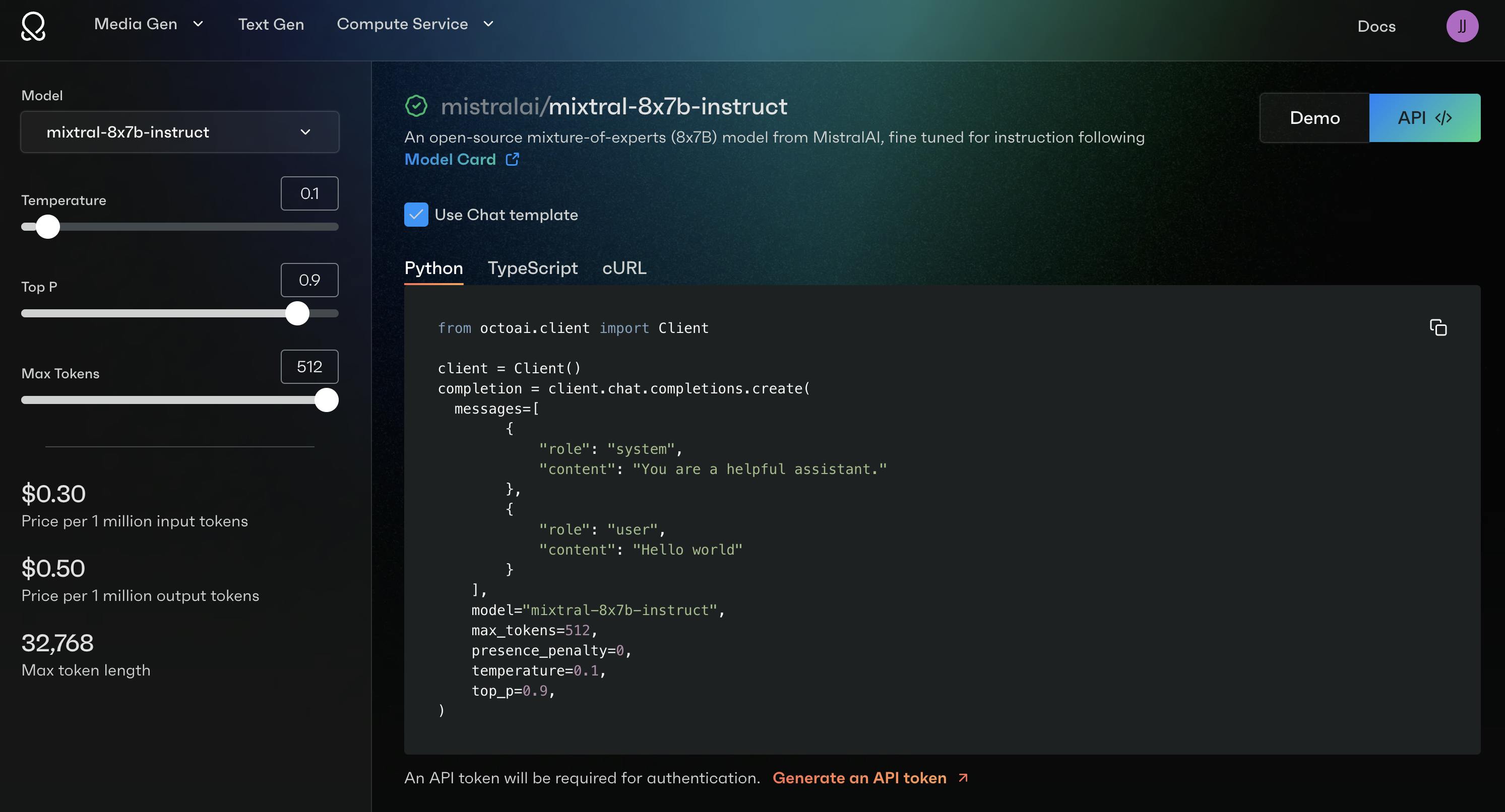
Click the Demo or API selections to enter our playground, where you can:
- Easily switch between all of our models, parameter counts, and quantization settings
- Test each model using our chat interface
- Adjust common settings such as
temperature - See the pricing and context limits for any selected model.

Selecting the “API” toggle will show you code samples in Python, TypeScript, and CURL format for calling the endpoint that you’ve selected, as well as key input & output parameters:
Billing
For pricing of all of these endpoints, please refer to our pricing page.
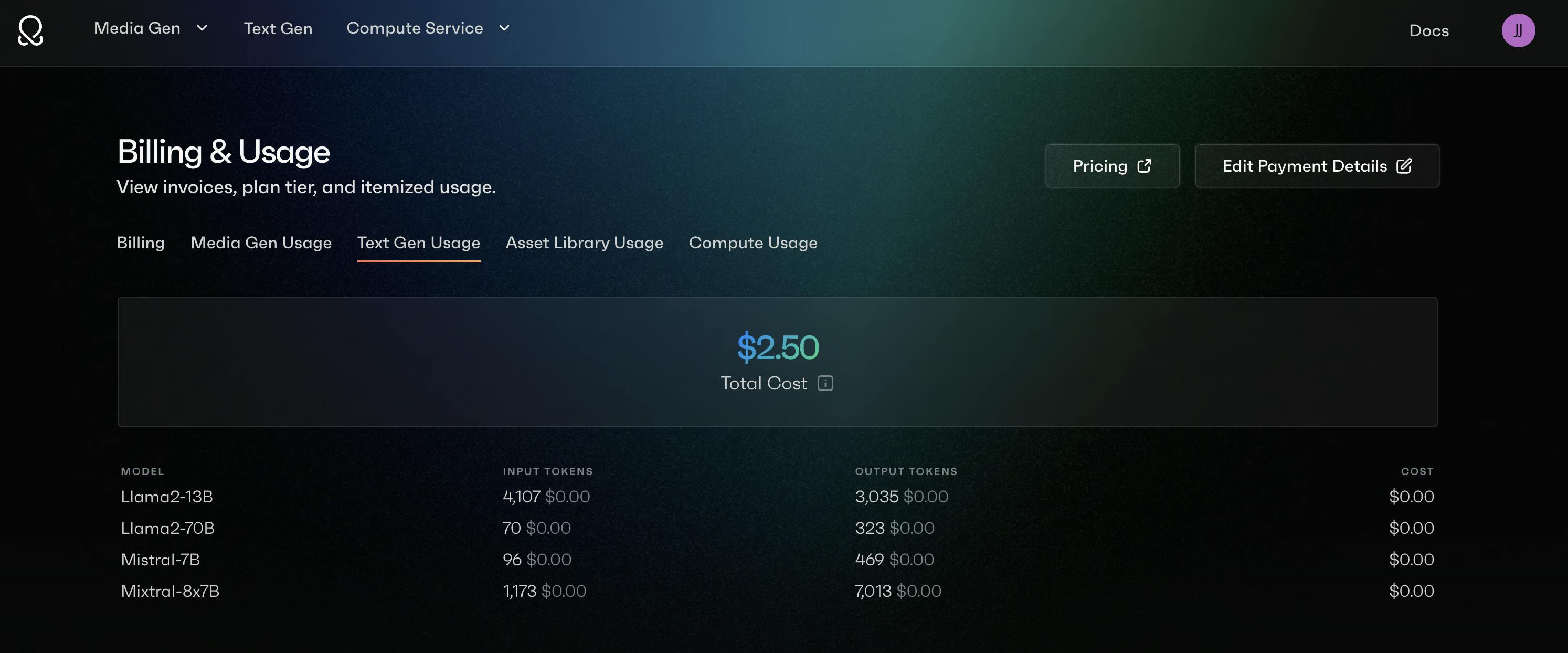
Once you provide billing information and generate an API key, any usage of these endpoints will be viewable under Accounts -> Billing & Usage -> Text Generation Usage. Note that these endpoints are very price competitive, so you’ll generally needs to rack up tens of thousands of tokens before you can see the charges!
API Docs
When you’re ready to start calling the endpoint programmatically, check out our REST API, Python SDK, and TypeScript SDK docs.