Quickstart
Quickstart
Start using our GenAI Solutions in one minute.
Welcome to OctoAI! Our mission is to enable users to harness value from the latest AI innovations by delivering efficient, reliable, and customizable AI systems for your apps. Run your models or checkpoints on our cost-effective API endpoints, or run our optimized GenAI stack in your environment.
Get started with inference
- Sign up for an account - new users get $10 of free credits
- Run your first inference:
- Navigate to a model page and click Get API Token:
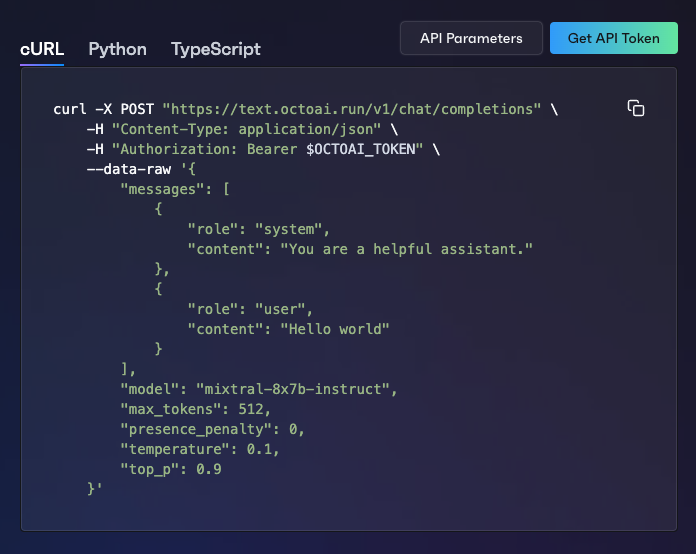
- Copy the code sample to run an inference:
cURL
Next steps
- Check out the wide variety of text generation models and media generation models models we support.
- Learn more about our Text Gen Solution, Media Gen Solution, or OctoStack.
- Explore our demos to see OctoAI in action.